
Apache Hadoop adalah kumpulan software utilitas open-source yang memfasilitasi penggunaan jaringan di banyak komputer untuk memecahkan masalah yang melibatkan data dan komputasi dalam jumlah besar. Hadoop menyediakan framework untuk penyimpanan terdistribusi dan pemrosesan data besar menggunakan model pemrograman MapReduce.
Awalnya dirancang untuk komputer cluster yang dibangun dari perangkat keras komoditas namun masih merupakan penggunaan umum, dan juga digunakan pada kelompok hardware high-end. Semua modul di Hadoop dirancang dengan asumsi mendasar bahwa kegagalan hardware adalah kejadian umum dan harus ditangani secara otomatis oleh framework itu sendiri.
Apache Hadoop 3.1 memiliki peningkatan yang nyata setiap perbaikan bug lebih dari rilis stabil 3.0 sebelumnya. Versi ini memiliki banyak peningkatan di HDFS dan MapReduce. Tutorial ini akan membantu Anda untuk menginstal dan mengkonfigurasi Hadoop 3.1.2 Single-Node Cluster di Ubuntu 18.04, 16.04 LTS dan Sistem LinuxMint. Artikel ini telah diuji dengan Ubuntu 18.04 LTS.
Langkah 1 – Prasyarat
Java adalah persyaratan utama untuk menjalankan Hadoop pada sistem apa pun, jadi pastikan Anda menginstal Java pada sistem Anda menggunakan perintah berikut.
Step 2 – Create User for Haddop
Kami sarankan untuk membuat akun normal untuk Hadoop berfungsi. Untuk membuat akun menggunakan perintah berikut.
adduser hadoop
Setelah membuat akun, perlu juga untuk mengatur ssh berbasis kunci ke akun sendiri. Untuk melakukan ini jalankan perintah berikut.
su - hadoop ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Sekarang, SSH ke localhost dengan user Hadoop. Ini seharusnya tidak meminta kata sandi, tetapi ketika ini adalah koneksi untuk pertama kali, sistem akan meminta untuk menambahkan RSA ke daftar host yang dikenal.
ssh localhost exit
Langkah 3 – Unduh Arsip Source Hadoop
Pada langkah ini, unduh file arsip source hadoop 3.1 menggunakan perintah di bawah ini. Anda juga dapat memilih download mirror untuk mencari server terdekat dengan Anda untuk meningkatkan kecepatan download. Yah meskipun Hanya ada dua, yaitu eropa dan usa, jadi kita pilih us. download source Hadoop mengunakan perintah wget.
cd ~ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz tar xzf hadoop-3.1.2.tar.gz mv hadoop-3.1.2 hadoop
Langkah 4 – Setup Hadoop Pseudo-Distributed Mode
4.1. Setup Variabel Environment Hadoop
Atur variabel lingkungan yang digunakan oleh Hadoop. Edit file ~/.bashrc dan tambahkan nilai berikut di akhir file.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Kemudian, setelah selesai save dan tutup file. dan jalankan perintah berikut agar perubahan segera diterapkan.
source ~/.bashrc
Sekarang edit $HADOOP_HOME/etc/hadoop/hadoop-env.sh file dan set variabel environment JAVA_HOME. Ubah jalur JAVA sesuai pengaturan instalasi di sistem Anda. Jalur ini dapat bervariasi sesuai versi sistem operasi dan sumber instalasi Anda. Jadi pastikan Anda menggunakan jalur yang benar.
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
kemudian tambahkan entri berikut ini.
export JAVA_HOME=/usr/lib/jvm/java-11-oracle
4.2. Setup Hadoop Configuration Files
Hadoop memiliki banyak file konfigurasi, yang perlu dikonfigurasi sesuai persyaratan infrastruktur Hadoop Anda. Mari kita mulai dengan konfigurasi dengan pengaturan dasar node tunggal Hadoop. pertama, navigasikan ke lokasi di bawah ini
cd $HADOOP_HOME/etc/hadoop
Edit core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Edit hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Edit mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Edit yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.3. Format Namenode
Sekarang format namenode menggunakan perintah berikut, pastikan direktori Storage adalah
hdfs namenode -format
Ini adalah Sample output :
WARNING: /home/hadoop/hadoop/logs does not exist. Creating. 2018-05-02 17:52:09,678 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = vmnode/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.1.2 ... ... ... 2018-05-02 17:52:13,717 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. 2018-05-02 17:52:13,806 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2018-05-02 17:52:14,161 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds . 2018-05-02 17:52:14,224 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2018-05-02 17:52:14,282 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at vmnode/127.0.1.1 ************************************************************/
Langkah 5 – Jalankan Cluster Hadoop
Mari mulai cluster Hadoop Anda menggunakan skrip yang disediakan oleh Hadoop. Cukup navigasikan ke direktori $HADOOP_HOME/sbin dan laksanakan skrip satu per satu.
cd $HADOOP_HOME/sbin/
Kemudian eksekusi skrip start-dfs.sh.
./start-dfs.sh
Kemudian eksekusi skrip start-yarn.sh.
./start-yarn.sh
Langkah 6 – Akses Layanan Hadoop di Browser
Hadoop NameNode dimulai pada port default 9870. Akses server Anda pada port 9870 di browser web favorit Anda.
http://ip-atau-domain:9870/
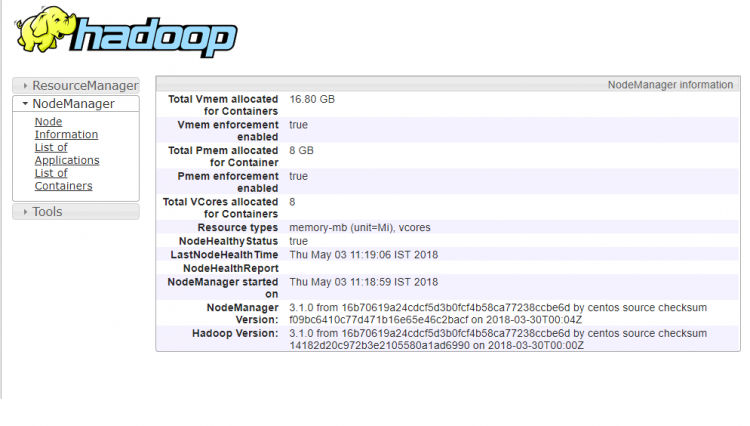
Sekarang akses port 8042 untuk mendapatkan informasi tentang cluster dan semua aplikasi
http://ip-atau-domain:8042/
Akses port 9864 untuk mendapatkan detail tentang node Hadoop Anda.
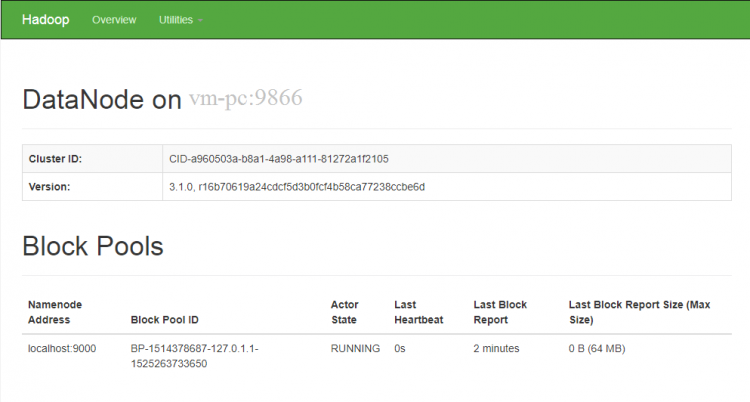
Langkah 7 – Uji Pengaturan Hadoop Node
7.1. Buat direktori HDFS diperlukan menggunakan perintah berikut.
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/hadoop
7.2. Salin semua file dari sistem file lokal /var/log/httpd ke file sistem terdistribusi hadoop menggunakan perintah di bawah ini
bin/hdfs dfs -put /var/log/apache2 logs
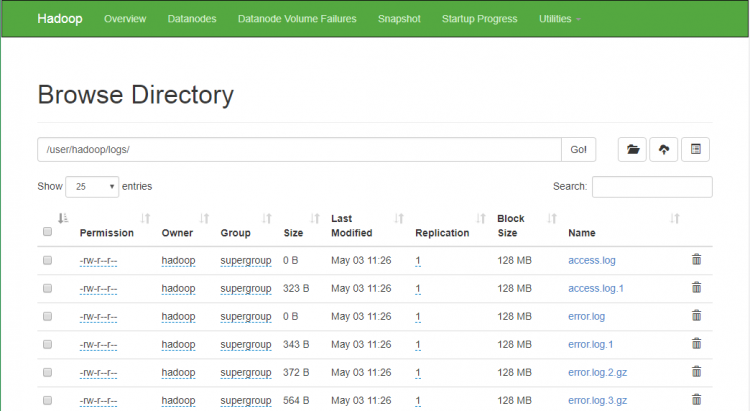
7.3. Jelajahi sistem file terdistribusi Hadoop dengan membuka URL di bawah ini di browser. Anda akan melihat folder apache2 dalam daftar. Klik pada nama folder untuk membuka dan Anda akan menemukan semua file log di sana.
http://ip-atau-domain:9870/explorer.html#/user/hadoop/logs/
7.4 – Sekarang salin direktori log untuk sistem file hadoop didistribusikan ke sistem file lokal.
bin/hdfs dfs -get logs /tmp/logs ls -l /tmp/logs/
Anda juga dapat memeriksa tutorial ini untuk menjalankan wordcount mapreduce contoh pekerjaan menggunakan baris perintah.

